Week 1 Machine Learning with Big Data
KNime - GUI based
Spark MLlib - inside Spark
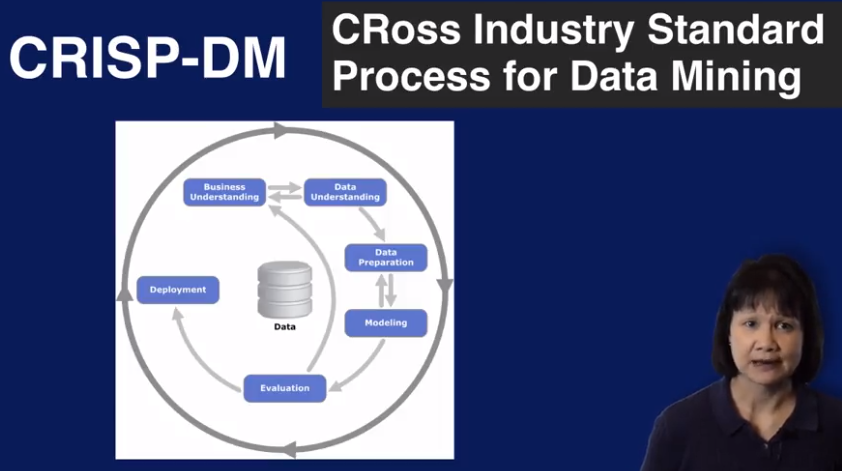
CRISP-DM

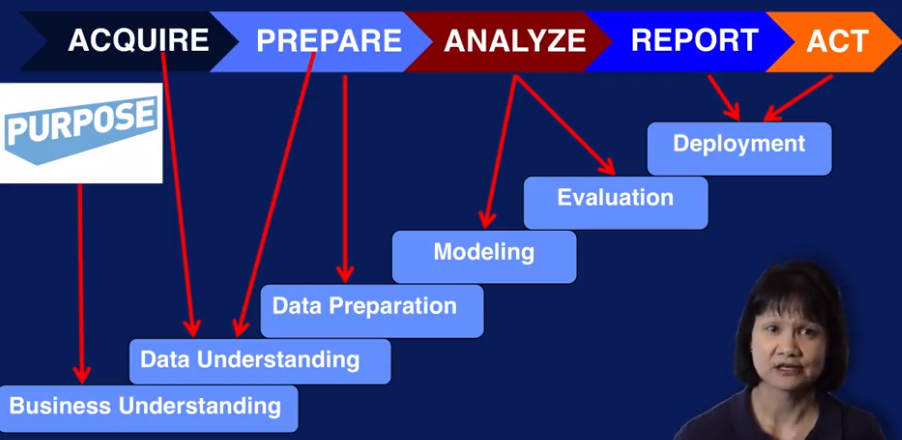
Week 2, Data Exploration
一般有两种方法,summary statistics 和 visualization

Summary statistics (mean 平均数,median 中位数, mode 最常见的数)


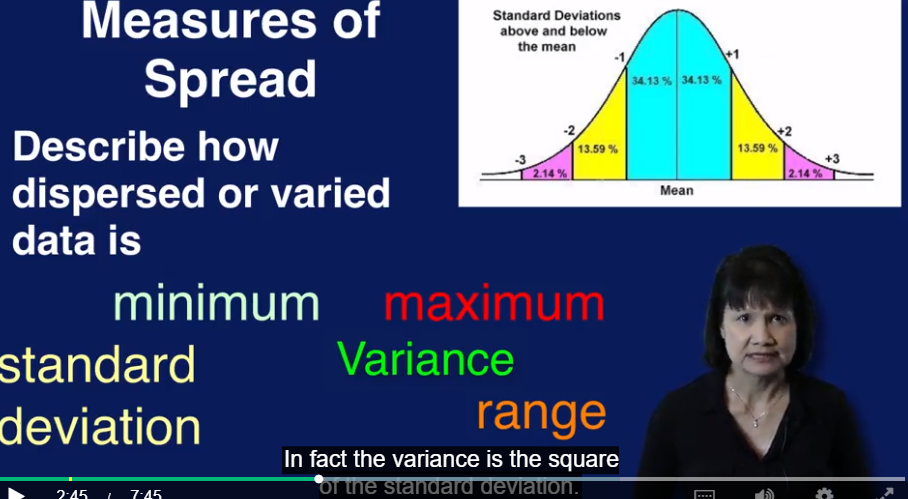
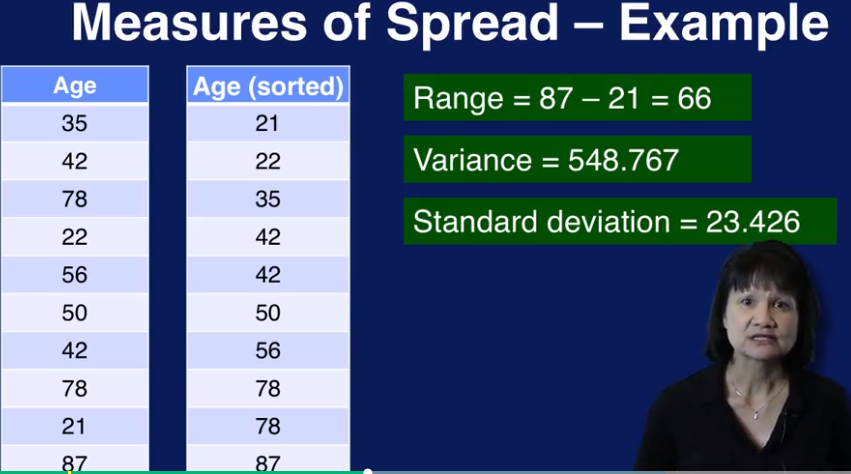
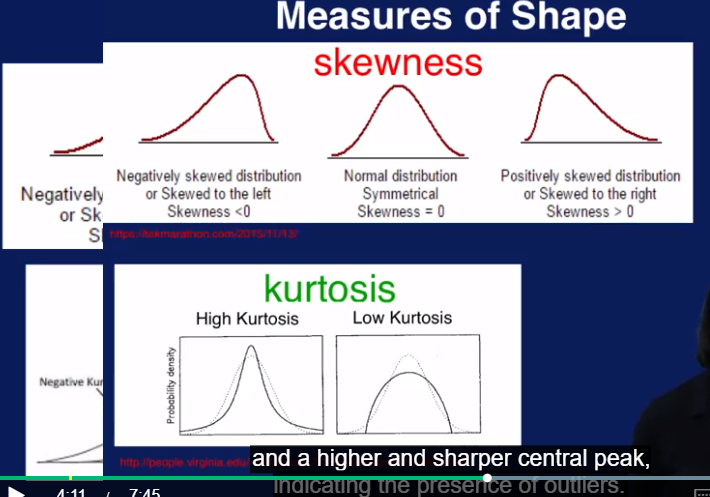
high Kurtosis 预示着有outlier的存在
visualization

这里详细讲一下 box plot
下图的 upper quartile 和 lower quartile 分别指的是 75% 和 25% 的点, median 很明显是中位数点,中间柱状部分的数据占了总数据的50%. Upper extreme 和 Lower extreme 分别是90% 和 10% 数据的点,超出部分就是outliers.

Data preparing


data wrangling 主要是transformation
